Flow Chart For Equity Transparency Calculations¶
Pip install the package using the link copied from GitHub¶
[1]:
!pip install git+https://github.com/European-Securities-Markets-Authority/esma_data_py.git
!pip install pandas
!pip install plotly
!pip install matplotlib
Collecting git+https://github.com/European-Securities-Markets-Authority/esma_data_py.git
Cloning https://github.com/European-Securities-Markets-Authority/esma_data_py.git to /tmp/pip-req-build-_6shr7oi
Running command git clone --filter=blob:none --quiet https://github.com/European-Securities-Markets-Authority/esma_data_py.git /tmp/pip-req-build-_6shr7oi
Resolved https://github.com/European-Securities-Markets-Authority/esma_data_py.git to commit 204a3d895a4b9dbe5b21268ef11b4d392eb58a21
Preparing metadata (setup.py) ... - done
Requirement already satisfied: pandas>=2.0.0 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from esma_data_py==0.0.1) (2.2.3)
Requirement already satisfied: tqdm>=4.65.0 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from esma_data_py==0.0.1) (4.67.1)
Requirement already satisfied: requests>=2.31.0 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from esma_data_py==0.0.1) (2.32.3)
Requirement already satisfied: numpy>=1.22.4 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas>=2.0.0->esma_data_py==0.0.1) (2.2.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas>=2.0.0->esma_data_py==0.0.1) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas>=2.0.0->esma_data_py==0.0.1) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas>=2.0.0->esma_data_py==0.0.1) (2025.2)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from requests>=2.31.0->esma_data_py==0.0.1) (3.4.1)
Requirement already satisfied: idna<4,>=2.5 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from requests>=2.31.0->esma_data_py==0.0.1) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from requests>=2.31.0->esma_data_py==0.0.1) (2.3.0)
Requirement already satisfied: certifi>=2017.4.17 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from requests>=2.31.0->esma_data_py==0.0.1) (2025.1.31)
Requirement already satisfied: six>=1.5 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from python-dateutil>=2.8.2->pandas>=2.0.0->esma_data_py==0.0.1) (1.17.0)
Building wheels for collected packages: esma_data_py
Building wheel for esma_data_py (setup.py) ... - done
Created wheel for esma_data_py: filename=esma_data_py-0.0.1-py3-none-any.whl size=17312 sha256=d4091cd964e54dafec17acfae1b8d1bcfb750740ecb5b8d956106accd4ceab7a
Stored in directory: /tmp/pip-ephem-wheel-cache-4ra029em/wheels/3a/75/9f/1e0eac5bdbd312da2963aa259fe36ec40e412d95f99c221049
Successfully built esma_data_py
Installing collected packages: esma_data_py
Successfully installed esma_data_py-0.0.1
Requirement already satisfied: pandas in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (2.2.3)
Requirement already satisfied: numpy>=1.22.4 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas) (2.2.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from pandas) (2025.2)
Requirement already satisfied: six>=1.5 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from python-dateutil>=2.8.2->pandas) (1.17.0)
Collecting plotly
Downloading plotly-6.0.1-py3-none-any.whl.metadata (6.7 kB)
Collecting narwhals>=1.15.1 (from plotly)
Downloading narwhals-1.32.0-py3-none-any.whl.metadata (9.2 kB)
Requirement already satisfied: packaging in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from plotly) (24.2)
Downloading plotly-6.0.1-py3-none-any.whl (14.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 14.8/14.8 MB 138.4 MB/s eta 0:00:00
Downloading narwhals-1.32.0-py3-none-any.whl (320 kB)
Installing collected packages: narwhals, plotly
Successfully installed narwhals-1.32.0 plotly-6.0.1
Collecting matplotlib
Downloading matplotlib-3.10.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (11 kB)
Collecting contourpy>=1.0.1 (from matplotlib)
Downloading contourpy-1.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (5.4 kB)
Collecting cycler>=0.10 (from matplotlib)
Downloading cycler-0.12.1-py3-none-any.whl.metadata (3.8 kB)
Collecting fonttools>=4.22.0 (from matplotlib)
Downloading fonttools-4.56.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (101 kB)
Collecting kiwisolver>=1.3.1 (from matplotlib)
Downloading kiwisolver-1.4.8-cp310-cp310-manylinux_2_12_x86_64.manylinux2010_x86_64.whl.metadata (6.2 kB)
Requirement already satisfied: numpy>=1.23 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from matplotlib) (2.2.4)
Requirement already satisfied: packaging>=20.0 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from matplotlib) (24.2)
Collecting pillow>=8 (from matplotlib)
Downloading pillow-11.1.0-cp310-cp310-manylinux_2_28_x86_64.whl.metadata (9.1 kB)
Collecting pyparsing>=2.3.1 (from matplotlib)
Downloading pyparsing-3.2.3-py3-none-any.whl.metadata (5.0 kB)
Requirement already satisfied: python-dateutil>=2.7 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from matplotlib) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages (from python-dateutil>=2.7->matplotlib) (1.17.0)
Downloading matplotlib-3.10.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (8.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.6/8.6 MB 123.4 MB/s eta 0:00:00
Downloading contourpy-1.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (324 kB)
Downloading cycler-0.12.1-py3-none-any.whl (8.3 kB)
Downloading fonttools-4.56.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (4.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.6/4.6 MB 137.9 MB/s eta 0:00:00
Downloading kiwisolver-1.4.8-cp310-cp310-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (1.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 162.1 MB/s eta 0:00:00
Downloading pillow-11.1.0-cp310-cp310-manylinux_2_28_x86_64.whl (4.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 4.5/4.5 MB 205.2 MB/s eta 0:00:00
Downloading pyparsing-3.2.3-py3-none-any.whl (111 kB)
Installing collected packages: pyparsing, pillow, kiwisolver, fonttools, cycler, contourpy, matplotlib
Successfully installed contourpy-1.3.1 cycler-0.12.1 fonttools-4.56.0 kiwisolver-1.4.8 matplotlib-3.10.1 pillow-11.1.0 pyparsing-3.2.3
Import libraries¶
[2]:
from esma_data_py import EsmaDataLoader
import os
from pathlib import Path
import plotly.express as px
import plotly.graph_objects as go
from matplotlib.colors import to_rgb
import pandas as pd
from tqdm import tqdm
from PIL import Image
Define color functions¶
[3]:
def hex_to_rgba(hex_color, alpha=1.0):
"""
Convert a hex color code to an RGBA string.
Args:
hex_color (str): A string representing the hex color (e.g., '#RRGGBB').
alpha (float, optional): The alpha (opacity) value for the color (default is 1.0).
Returns:
str: The color in 'rgba(r, g, b, alpha)' format.
"""
hex_color = hex_color.lstrip('#') # Remove the '#' if present
if len(hex_color) != 6:
raise ValueError("Hex color must be in the format #RRGGBB.")
r, g, b = tuple(int(hex_color[i:i+2], 16) for i in (0, 2, 4))
return f'rgba({r}, {g}, {b}, {alpha})'
def rgb_to_rgba(rgb_color, alpha=1.0):
"""
Convert an RGB color string to an RGBA string.
Args:
rgb_color (str): A string representing the RGB color (e.g., 'rgb(r, g, b)').
alpha (float, optional): The alpha (opacity) value for the color (default is 1.0).
Returns:
str: The color in 'rgba(r, g, b, alpha)' format.
"""
# Strip off 'rgb(' and ')'
rgb_color = rgb_color[rgb_color.find('(')+1:rgb_color.find(')')]
r, g, b = map(int, rgb_color.split(','))
return f'rgba({r}, {g}, {b}, {alpha})'
def named_to_rgba(named_color, alpha=1.0):
"""
Convert a named color to an RGBA string.
Args:
named_color (str): The name of the color (e.g., 'red', 'blue').
alpha (float, optional): The alpha (opacity) value for the color (default is 1.0).
Returns:
str: The color in 'rgba(r, g, b, alpha)' format.
"""
try:
r, g, b = to_rgb(named_color)
except ValueError:
raise ValueError(f"Invalid named color: {named_color}")
return f'rgba({int(r*255)}, {int(g*255)}, {int(b*255)}, {alpha})'
def convert_to_rgba(color, alpha=1.0):
"""
Convert a color in different formats (hex, rgb, named) to an RGBA string.
Args:
color (str): A color in either hex ('#RRGGBB'), rgb ('rgb(r, g, b)'), or a named color (e.g., 'red').
alpha (float, optional): The alpha (opacity) value for the color (default is 1.0).
Returns:
str: The color in 'rgba(r, g, b, alpha)' format.
"""
if color.startswith('#'):
return hex_to_rgba(color, alpha)
elif color.startswith('rgb'):
return rgb_to_rgba(color, alpha)
else:
return named_to_rgba(color, alpha)
# Concatenate different qualitative color sets from Plotly
colors = px.colors.qualitative.Set1 + \
px.colors.qualitative.Set2 + \
px.colors.qualitative.Set3 + \
px.colors.qualitative.Pastel1 + \
px.colors.qualitative.Pastel2
# Define the opacity
opacity = 0.3
# Convert each color to RGBA format with the specified opacity
rgba_colors = [convert_to_rgba(color, alpha=opacity) for color in colors]
Define plot and ds functions¶
[4]:
def make_sankey_plot(df, id1, id2, value, title='', title_left="<b>Year-1<b>", title_right="<b>Year<b>", opacity=0.3):
"""
Creates a Sankey plot to visualize the flow of values between two categorical variables in the dataframe.
Parameters:
- df (pd.DataFrame): Input dataframe containing the data.
- id1 (str): Column name representing the first category (e.g., previous year).
- id2 (str): Column name representing the second category (e.g., current year).
- value (str): Column name representing the values to be visualized in the Sankey plot.
- title (str, optional): Title for the plot. Defaults to an empty string.
- title_left (str, optional): Title for the left side of the plot (default is "<b>Year-1<b>").
- title_right (str, optional): Title for the right side of the plot (default is "<b>Year<b>").
- opacity (float, optional): Opacity for the Sankey plot colors (default is 0.3).
Returns:
- fig (plotly.graph_objects.Figure): The Sankey plot figure.
- data (pd.DataFrame): Dataframe containing the prepared data for the Sankey plot.
"""
# Format the id columns to include 'Year_' as prefix
id1, id2 = f"Year_{id1}", f"Year_{id2}"
# Prepare the dataframe by selecting necessary columns and converting to string type
df = df[[id1, id2, value]].astype(str)
# Create a sorted list of unique categories from both id1 and id2 columns
list_thrs_id1 = list(df[id1].value_counts().index)
list_thrs_id2 = list(df[id2].value_counts().index)
list_thrs = sorted(set(list_thrs_id1 + list_thrs_id2))
# Create label dataframes for id1 and id2 categories
df_lis_label = (pd.DataFrame({id1: list_thrs})
.sort_values([id1], ascending=True)
.reset_index(drop=True)
.assign(id_ = lambda x: x.apply(lambda y: y.name, axis=1))
.rename(columns = {'id_': id1 + '_id'}))
df_lis_fitrs_label = (pd.DataFrame({id2: list_thrs})
.sort_values([id2], ascending=True)
.reset_index(drop=True)
.assign(id_ = lambda x: x.apply(lambda y: y.name + len(df_lis_label.index), axis=1))
.rename(columns = {'id_': id2 + '_id'}))
# Define a list of colors for the nodes
colors = px.colors.qualitative.Set1 + \
px.colors.qualitative.Set2 + \
px.colors.qualitative.Set3 + \
px.colors.qualitative.Pastel1 + \
px.colors.qualitative.Pastel2
# Ensure we have enough colors to cover all unique categories
while len(colors) < len(list_thrs):
colors += colors
# Convert colors to RGBA format with specified opacity
rgba_colors = [convert_to_rgba(color, alpha=opacity) for color in colors]
# Prepare color mapping for each category
df_colors = pd.DataFrame({"list_id": list_thrs,
"color": colors[:len(list_thrs)],
"color_light": rgba_colors[:len(list_thrs)]})
# Merge the label dataframes with the color mapping for a final dataframe
df_colors2 = (pd.concat([df_lis_fitrs_label.rename(columns = {id2: 'list_id', id2 + '_id': 'id_'}),
df_lis_label.rename(columns = {id1: 'list_id', id1 + '_id': 'id_'})])
.merge(df_colors, on="list_id", how='left')
.sort_values(['id_'], ascending=True))
# Aggregate data and prepare for Sankey plot
data = (df[[id1, id2, value]].groupby([id1, id2], as_index=False)
.count()
.merge(df_lis_fitrs_label, on=id2, how='left')
.merge(df_lis_label, on=id1, how='left')
.merge(df_colors.rename(columns = {'list_id': id1}), on=id1, how='left'))
# Calculate percentages of items in the same and different buckets (id1 == id2 vs id1 != id2)
n_isin_same_bucket = sum(data.query(f"{id1} == {id2}")[value])
n_isin_different_bucket = sum(data[value]) - sum(data.query(f"{id1} == {id2}")[value])
pct_isin_same_bucket = n_isin_same_bucket / sum(data[value]) * 100
pct_isin_different_bucket = n_isin_different_bucket / sum(data[value]) * 100
# Prepare caption to show in the plot
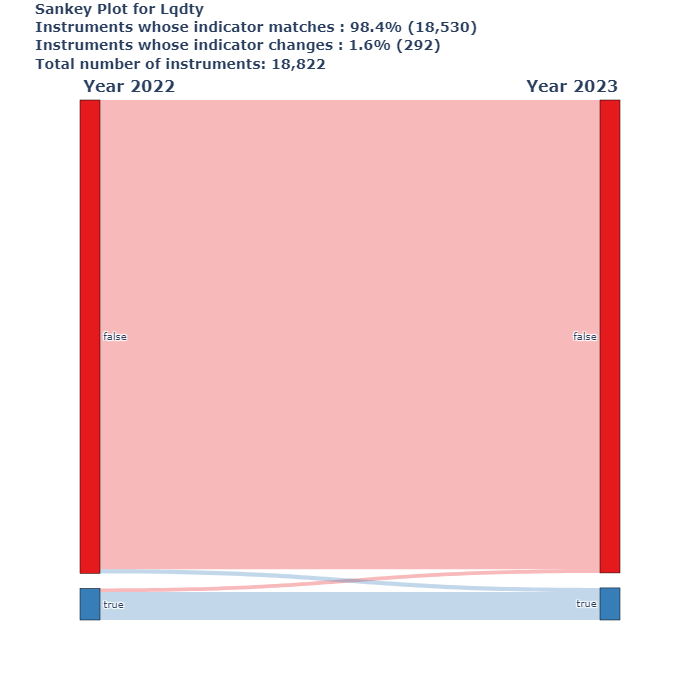
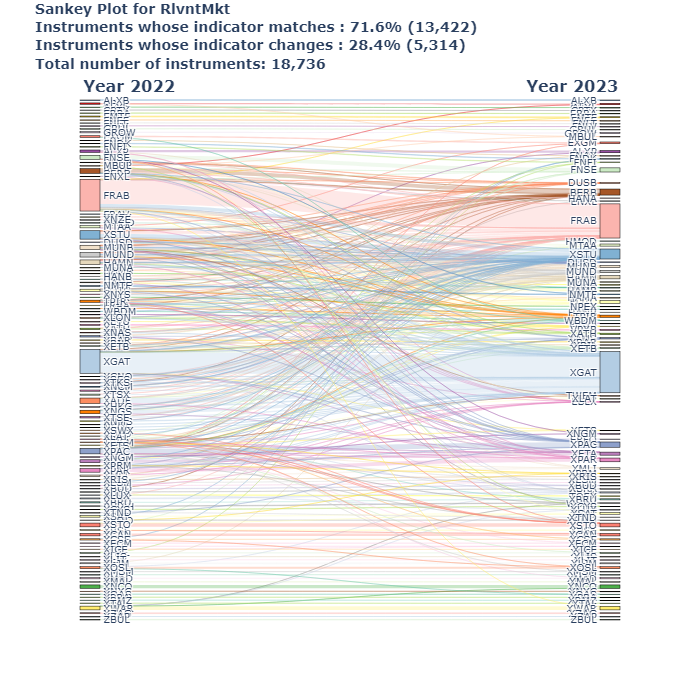
add_caption = f"<br>Instruments whose indicator matches : <b>{pct_isin_same_bucket:.1f}%<b> ({n_isin_same_bucket:,.0f})"
add_caption += f"<br>Instruments whose indicator changes : <b>{pct_isin_different_bucket:.1f}%<b> ({n_isin_different_bucket:,.0f})"
add_caption += f"<br>Total number of instruments: {sum(data[value]):,.0f}"
data['matching_ratio'] = pct_isin_same_bucket
# Add the caption to the title
title = "<b>" + title + "<b>"
title += add_caption
# Prepare data for Sankey plot
source = list(data[id2 + '_id'])
target = list(data[id1 + '_id'])
values = list(data[value])
color = list(data['color_light'])
# Create the Sankey plot using Plotly
fig = go.Figure(data=[go.Sankey(node = dict(pad = 15,
thickness = 20,
line = dict(color = "black", width = 0.5),
label = list(df_colors2['list_id']),
color = list(df_colors2['color'])),
link = dict(source = source,
target = target,
value = values,
label = values,
color = color ))])
# Update layout of the plot (fonts, size, etc.)
fig = fig.update_layout(font_size=10,
width=700,
height=700,
plot_bgcolor='white',
xaxis={'showgrid': False,
'zeroline': False,
'visible': False},
yaxis={'showgrid': False,
'zeroline': False,
'visible': False,},
title={'text' : title,
'y': 0.98})
# Add annotations for the titles of the left and right sides of the plot
for x_coordinate, column_name in enumerate([title_left, title_right]):
fig = fig.add_annotation(x=x_coordinate,
y=1.05,
xref="x",
yref="paper",
text=column_name,
showarrow=False,
font=dict(size=16),
align="center")
return fig, data
def create_sankey_datasets(df, year_1, year_2, columns_to_process):
"""
This function processes a given dataframe to create datasets for Sankey plots and generates the plots themselves
for specific columns representing different attributes across two given years.
Parameters:
df (pd.DataFrame): The input dataframe containing the data to process.
year_1 (str): The first year to filter the data (e.g., '2022').
year_2 (str): The second year to filter the data (e.g., '2023').
columns_to_process (list): A list of column names that should be processed for creating the Sankey plots.
Returns:
sankey_datasets (dict): A dictionary where keys are column names and values are the corresponding processed DataFrames.
sankey_plots (dict): A dictionary where keys are column names and values are the corresponding Sankey plot objects.
"""
# Split the data into two datasets based on the years provided
df_year1 = df.loc[lambda x: x.FrDt.str.startswith(year_1)]
df_year2 = df.loc[lambda x: x.ToDt.str.startswith(year_2)]
# Initialize dictionaries to store the resulting datasets and plots
sankey_datasets = {}
sankey_plots = {}
# Iterate over the columns to be processed for the Sankey plots
for column in tqdm(columns_to_process):
# Create subsets of the data for the current column for each year
df_year1_subset = df_year1[['Id', column]].rename(columns={column: f'Year_{year_1}'})
df_year2_subset = df_year2[['Id', column]].rename(columns={column: f'Year_{year_2}'})
# Merge the two subsets on the 'Id' to align the data from both years
merged_df = pd.merge(df_year1_subset, df_year2_subset, on='Id', how='outer')
# Drop rows where there is missing data for either year
merged_df = merged_df.dropna(subset=[f'Year_{year_1}', f'Year_{year_2}'])
# Remove duplicate entries to ensure clean data
merged_df = merged_df.drop_duplicates()
# Store the cleaned and merged DataFrame for the current column
sankey_datasets[column] = merged_df
# Generate the Sankey plot for the merged dataset
sankey_plot, sk = make_sankey_plot(df=merged_df,
id1=year_1,
id2=year_2,
value="Id",
title=f"Sankey Plot for {column}",
title_left=f"<b>Year {year_1}<b>",
title_right=f"<b>Year {year_2}<b>")
# Store the generated Sankey plot in the dictionary
sankey_plots[column] = sankey_plot
# Return the dictionaries containing the datasets and plots
return sankey_datasets, sankey_plots
def display_saved_img(img_path):
"""
Changes working directory to '_static' and displays the image at `img_path`.
Parameters:
img_path (str): Path to the image file.
"""
picture_link = Path.cwd().parent / '_static'
if os.path.exists(picture_link):
os.chdir(picture_link)
img = Image.open(f'{img_path}').convert("RGB")
display(img)
Initialize EsmaDataLoader¶
[5]:
# Initialize edl with creation dates to, if not set:
# creation_date_to = Today
# creation_date_from = 2017-01-01
edl = EsmaDataLoader(creation_date_from='2024-03-01', creation_date_to='2024-03-03')
[6]:
# Load latest files, if no arguments are specified:
# file_type = 'Full'
# vcap = False (True if dvcap files to retrieve)
# isin = []
# cfi = 'E'
# eqt=True # Determines (If filter for only equity instruments)
# update = False (Parameter used for caching, flag to True to re download the df as the latest version)
df = edl.load_latest_files()
2025-03-25 14:27:28,751 - EsmaDataLoader - INFO - Requesting fitrs files
2025-03-25 14:27:29,342 - EsmaDataLoader - INFO - Request successful, parsing response
2025-03-25 14:27:29,366 - EsmaDataLoader - INFO - Downloading 1 files
2025-03-25 14:27:29,367 - EsmaDataLoader - INFO - Downloading and parsing https://fitrs.esma.europa.eu/fitrs/FULECR_20240302_E_1of1.zip
Parsing file ... : 100%|██████████| 157464/157464 [00:04<00:00, 36905.66it/s]
/home/docs/checkouts/readthedocs.org/user_builds/esma-data-py/envs/latest/lib/python3.10/site-packages/esma_data_py/utils/utils.py:328: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
delivery_df = df.applymap(lambda x: x[0] if isinstance(x, list) else x)
2025-03-25 14:27:45,549 - EsmaDataUtils - INFO - Data saved: /home/docs/esma_data_py/data/9078974700b62db57e717dfbf8f8a70b.csv
2025-03-25 14:27:45,550 - EsmaDataLoader - INFO - Process done!
Custom preprocessing¶
[7]:
# Custom filtering for this specific process
df = df.query("Mthdlgy == 'YEAR'").query("FrDt >= '2022-01-01'")
df = df.rename(columns={'Id_2': 'RlvntMkt'})
Plots creation¶
[8]:
# Create plots
sankey_datasets, sankey_plots = create_sankey_datasets(df=df,
year_1="2022",
year_2="2023",
columns_to_process= ["RlvntMkt", "LrgInScale", "Lqdty"])
100%|██████████| 3/3 [00:00<00:00, 8.20it/s]
[9]:
for img in os.listdir(Path.cwd().parent / '_static'):
display_saved_img(img)

[ ]: